Distroless
What
ML development relies a lot on large computation frameworks like torch / tensorflow and wrappers on top of them and we became kind of locked on Python ecosystem. So we got used to deploy python to production.
For the virtualization, we usually use containers.
It all comes with the cost of bringing lots of dependencies to our application containers, which leads to huge image sizes and lots of security issues (literally thousands, if you don’t update python version/libs versions too often).
The question is - can we somehow bring only needed pieces of our software stack to prod to reduce the size and increase security of our application?
How
The basic idea is to deploy only what’s used at application runtime.
And we have multiple choices, including:
- stay with containers and try to create minimalistic image: multi-stage build with minimal-possible final stage;
- go into something more low-level, like unikernels (but let’s cover it separately);
Let’s explore the first approach in more detail.
Bring only libraries that app uses
Python libs rely on the compiled shared libraries, part of them stored in wheels that you downloaded from pypi, but part - should be placed in the common linux directory like /usr/lib/x86_64-linux-gnu/.
To solve most part of security issues, it’s usually enough to update the dependencies. The only problem could be with “core” ML dependencies like tensorflow or torch which we usually use for inference - we need to update them carefully since prediction results could become slightly different from version to version.
For example, here are some of the shared libs that needed to run gunicorn web-server (a default one for python web apps):
/usr/lib/x86_64-linux-gnu/libcrypto.so.1.1
/usr/lib/x86_64-linux-gnu/libffi.so.7
/usr/lib/x86_64-linux-gnu/libffi.so.7.1.0
/usr/lib/x86_64-linux-gnu/libglib-2.0.so.0
/usr/lib/x86_64-linux-gnu/libglib-2.0.so.0.6400.6
/usr/lib/x86_64-linux-gnu/libgthread-2.0.so.0
/usr/lib/x86_64-linux-gnu/libgthread-2.0.so.0.6400.6
/usr/lib/x86_64-linux-gnu/libssl.so.1.1
Split the container image assembly into two stages
So we can adopt approach widely used with compiled languages:
- “build“: get some “regular” base image with lots of libraries → install project dependencies (examples: python-slim, cuda-ubuntu)
- — analyse which libs python app is using at runtime —
- “runtime“: starting from a very “thin“ image (examples: alpine, distroless) copy needed files from the first stage. Ideally it could be just scratch, if we could easily statically compile our apps ;)
Implementation
Create Dockerfile as usual, for example like this:
FROM python:3.9.2-slim as py
ARG DEBIAN_FRONTEND=noninteractive
RUN apt-get clean && apt-get update && \
apt-get -y install --no-install-recommends \
build-essential \
libev-dev \
ca-certificates \
software-properties-common \
openssh-client \
strace \
&& \
rm -rf /var/lib/apt/lists/*
COPY requirements.txt /app/requirements.txt
WORKDIR /app
RUN pip install -U pip && python3 -m pip install -r requirements.txt
RUN apt-get update \
&& apt-get purge -y \
build-essential \
&& apt-get clean \
&& apt-get autoremove -y \
&& rm -rf /var/lib/apt/lists/* /tmp/* /var/cache/apt/*
Determine which shared libs need to be picked
The idea is to run application inside a container and track which fopen (and similar) sys-calls the app process uses. So we can find all the shared libs that the process really need to operate. Here is what you need to do:
- build the container with all needed dependencies (w/o adding second stage yet). Don’t forget to install
strace - run container with the shared volume to keep trace files on the host machine:
docker run --rm -it \ --name=<service-name> \ -v /tmp/traces:/traces \ --entrypoint /bin/sh \ <service-name>:latest - go to the running container’s shell and collect trace log of the running app:
strace -fe trace=open,openat,name_to_handle_at -o /traces/run.trace ./serve.sh
After logs has been collected - let’s get only those libs which relates to the needed OS deps.
Create the script, let’s call it trace_analyze.sh (change grep patterns to include/exclude paths depending on your needs):
#!/bin/bash
# Apps needed to run that script:
# echo, grep, cat, sort, uniq
# Check if at least one filename is provided
if [ "$#" -lt 1 ]; then
echo "Usage: $0 <file1> [<file2> ...]"
exit 1
fi
GREP_CMD="grep"
if [[ $(uname -s) == *Darwin* ]]; then
GREP_CMD="ggrep"
fi
# Concatenate the content of the specified files
concatenated_content=$(cat "$@")
echo "$concatenated_content" \
| $GREP_CMD -E '/lib/x86_64-linux-gnu/|/usr/lib/x86_64-linux-gnu/|/usr/local/cuda/lib64/' \
| $GREP_CMD -v -E '/usr/local/lib/python|opencv_python|etc|libJitPI|.cache|python3[^/]+\.so|/lib/x86_64-linux-gnu/tls/|/usr/lib/x86_64-linux-gnu/tls/|libittnotify.so|/glibc-hwcaps/' \
| $GREP_CMD -oP '(?<=\").*?(?=\")' \
| sort | uniq
And run it against the collected file with traces:
./trace_analyze.sh /tmp/traces/*.trace > trace_filtered.txt
You will get the list of libs in the following format:
/lib/x86_64-linux-gnu/libbz2.so.1.0.4
/lib/x86_64-linux-gnu/libz.so
/usr/lib/x86_64-linux-gnu/libGL.so.1
/usr/lib/x86_64-linux-gnu/libc.so.6 // <-- drop
/usr/lib/x86_64-linux-gnu/libGLX.so.0
/usr/lib/x86_64-linux-gnu/libGLdispatch.so.0
...
You need to drop some core os dependencies that could lead to errors at runtime, like libc, pthread, etc.
Save the resulting list of libs somewhere.
Distroless as a second stage
We can continue with using python-distroless for the second stage. It’s a way to deploy very minimalistic containers dropping a lot of unnecessary code from OS. It’s well-adopted by tech giants like Google, Facebook, etc. It has a benefit of being one of the smallest possible choices with pre-installed fully-fledged python interpreter.
So your Dockerfile could look like this:
...
# Create group and user for app runtime
RUN groupadd -g 1001 -r app && \
useradd -u 1001 -r -d /app -g app app
# Save `app` user data separately, it will always be the last row
RUN tail -n 1 /etc/passwd > /passwd && \
tail -n 1 /etc/group > /group && \
tail -n 1 /etc/gshadow > /gshadow
# Python 3.9
FROM artifactory.tools.devrtb.com/docker-virtual/distroless/python3-debian11-zlib1g1-3:1.0.0
# python packages
COPY --from=py /usr/local/lib/python3.9/site-packages /site-packages
ENV PYTHONPATH=/site-packages
ENV LANG C.UTF-8
Copy executables needed to run app/tests:
...
COPY --from=py \
/usr/local/bin/gunicorn \
/usr/bin/
# system level shared libs
COPY --from=py \
/lib/x86_64-linux-gnu/libpcre.so.3 \
/lib/x86_64-linux-gnu/
COPY --from=py \
/usr/lib/x86_64-linux-gnu/libwebp.so.6.0.2 \
/usr/lib/x86_64-linux-gnu/libwebp.so.6 \
/usr/lib/x86_64-linux-gnu/libwebpmux.so.3.0.1 \
/usr/lib/x86_64-linux-gnu/libwebpmux.so.3 \
/usr/lib/x86_64-linux-gnu/libGL.so.1 \
/usr/lib/x86_64-linux-gnu/libGLX.so.0 \
/usr/lib/x86_64-linux-gnu/libGLdispatch.so.0 \
/usr/lib/x86_64-linux-gnu/libX11.so.6 \
/usr/lib/x86_64-linux-gnu/libXau.so.6 \
/usr/lib/x86_64-linux-gnu/libXdmcp.so.6 \
/usr/lib/x86_64-linux-gnu/libXext.so.6 \
/usr/lib/x86_64-linux-gnu/libbsd.so.0 \
/usr/lib/x86_64-linux-gnu/libcrypto.so.1.1 \
/usr/lib/x86_64-linux-gnu/libffi.so.6 \
/usr/lib/x86_64-linux-gnu/libglib-2.0.so.0 \
/usr/lib/x86_64-linux-gnu/libgthread-2.0.so.0 \
/usr/lib/x86_64-linux-gnu/libssl.so.1.1 \
/usr/lib/x86_64-linux-gnu/libstdc++.so.6 \
/usr/lib/x86_64-linux-gnu/libxcb.so.1 \
/usr/lib/x86_64-linux-gnu/
Copy user credentials and files, specifying the owner (app in this case):
...
# copy `app` user credentials
COPY --from=py \
/passwd \
/group \
/gshadow \
/etc/
COPY --chown=app:app --chmod=744 . /app/service
Finally, you need to specify env variables and define the entrypoint. But keep in mind that it could be only sh or no shell at all. For example in deb11 simple shell is still presented, and I’ve used it to run the app:
...
ENTRYPOINT { /bin/sh /app/service/serve_distroless.sh; }
Also, in your runner script, usually it is better to specify full paths to executables, like /usr/local/bin/gunicorn.
Add CUDA support
Basically, everything said in the previous section stays the same, except that you can use specialized cuda image as a base one, like that:
FROM nvidia/cuda:11.7.1-cudnn8-runtime-ubuntu20.04 as py
In case of pytorch - it already has needed cuda libs shipped inside a wheel, the only thing is that host machine should share the device properly. In case of other dl frameworks, like tensorflow, you may need to copy some libs like lubcudnn.so and libcudart.so to the second stage (like described here).
Results
Setup:
- g5.x2large EC2 VM with ubuntu based AMI for torch 1.13.1
- dive used for built image analysis
Here are some results for two applications:
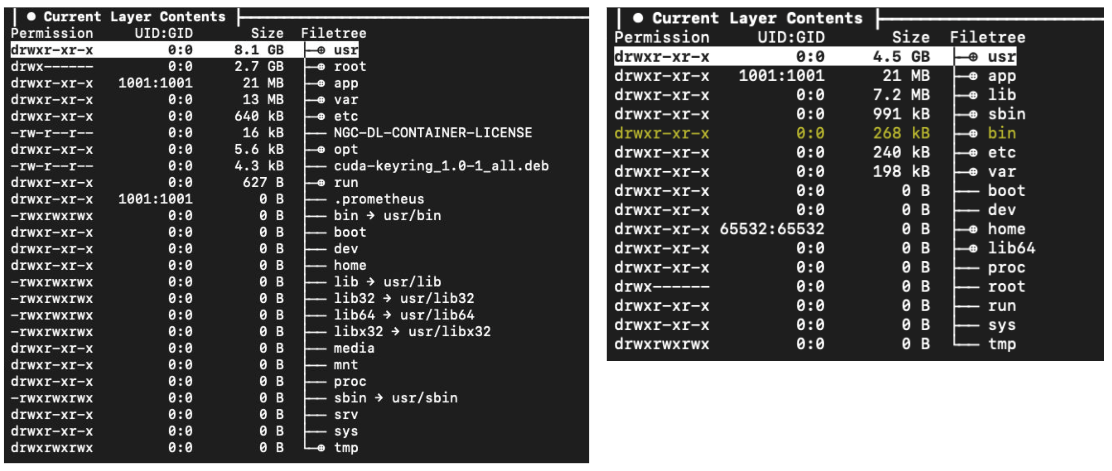
- CPU-based one. First clear benefit - image size reduction: ~2.3 Gb vs ~1.3 Gb → decreased image delivery time. You can see the differences below (on the left - old way, on the right - distroless):
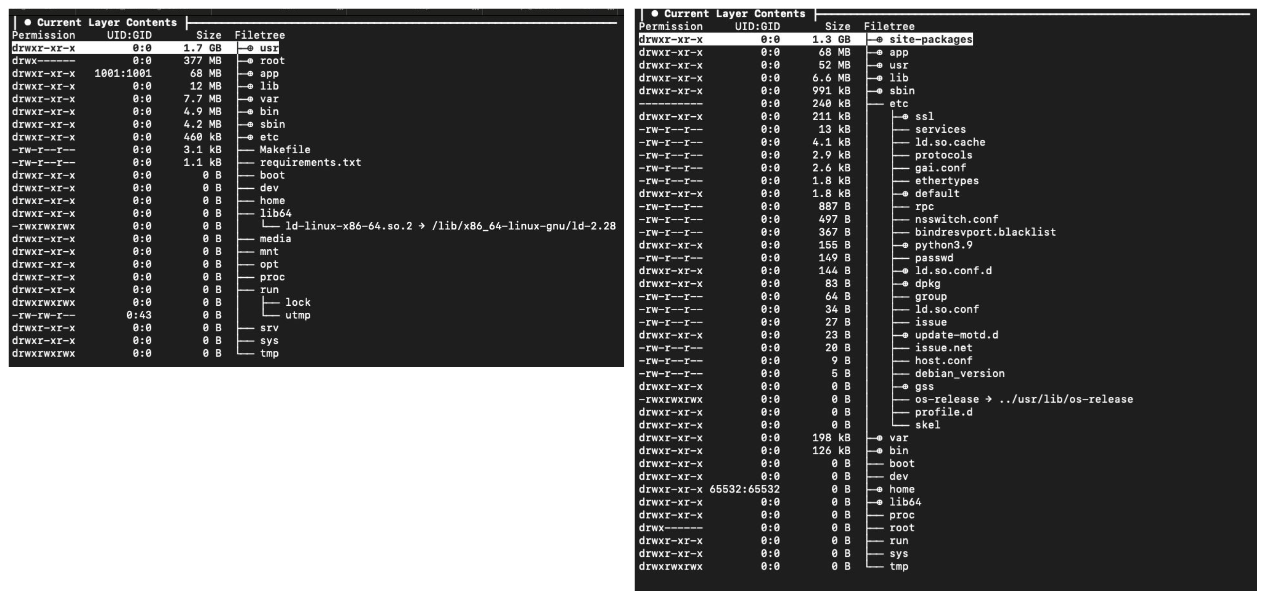
- Next application uses CUDA. We can reduce the size of the resulting image more than x2 times, for pytorch, if we copy only torch python package into the distroless part, without need to copy other cuda libs (and even use just python-slim as a base image instead of ubuntu with cuda). In the end the difference is: ~11 Gb vs ~4.5 Gb.